出典: ハート・オブ・ザ・マシン 画像ソース: Unbounded AI によって生成瞬く間に、オープンソースのビッグモデルは再び改良されました。 Google と OpenAI には本当に外堀がないのでしょうか?「30 分間の昼休みを取ったところですが、私たちの分野はまた変わってしまったのでしょうか?」 最新のオープンソース大型モデルのランキングを見て、AI 分野の起業家は自分の魂に問いかけました。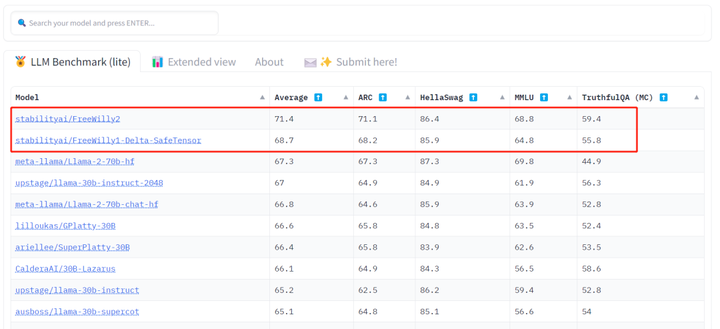 リーダーボードのリンク:上の赤いボックス内の「ルーキー」は、Stability AI と CarperAI lab の 2 つの大きなモデル、FreeWilly 1 と FreeWilly 2 です。たった今、彼らは 3 日前に Meta によってリリースされた Llama-2-70b-hf を上回り、HuggingFace の Open LLM リーダーボードのトップに到達することに成功しました。さらに驚くべきことは、FreeWilly 2 は多くのベンチマークで ChatGPT (GPT-3.5) も上回り、GPT-3.5 と実際に競合できる最初のオープンソース モデルとなったことですが、これは Llama 2 にはできなかったことです。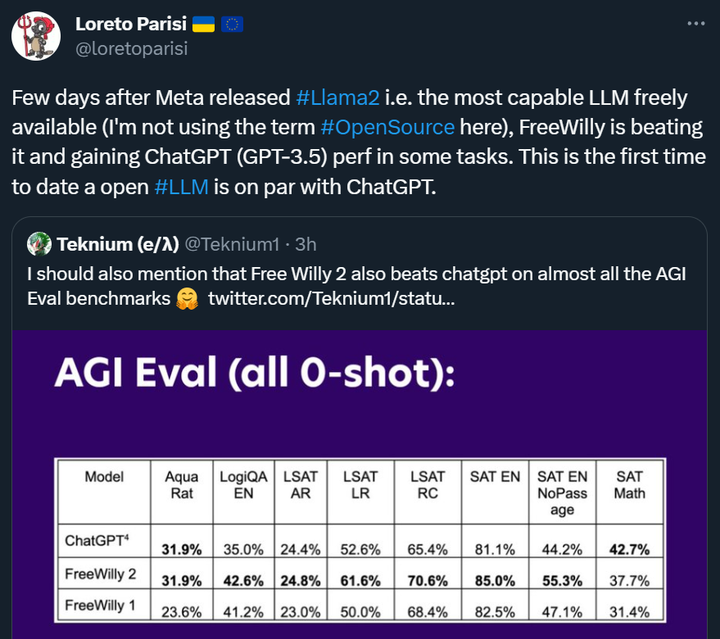 FreeWilly 1 は、オリジナルの LLaMA 65B ベース モデルと、標準 Alpaca 形式の新しい合成データセットを使用した注意深く監視された微調整 (SFT) に基づいて構築されています。 FreeWilly2 は、最新の LLaMA 2 70B ベース モデルをベースにしています。Stability AI が公開したブログから、これら 2 つの新しいモデルの詳細を確認できます。## **データ ソース**FreeWilly モデルのトレーニング方法は、Microsoft が論文「Orca: GPT-4 の複雑な説明トレースからの進歩的学習」で開拓した方法に直接影響を受けています。 FreeWilly のデータ生成プロセスは似ていますが、データのソースに違いがあります。FreeWilly のデータセットには 600,000 のデータ ポイント (元の Orca 論文で使用されたデータセット サイズの約 10%) が含まれており、Enrico Shippole によって作成された次の高品質の命令データセットから言語モデルをインスピレーションとして生成されました。* COTサブミックスオリジナル* NIV2 サブミックス オリジナル* FLAN 2021 サブミックス オリジナル* T0 サブミックス オリジナルこのアプローチを使用して、研究者らは、より単純な LLM モデルを使用して 500,000 の例を生成し、より複雑な LLM モデルを使用してさらに 100,000 の例を生成しました。公平な比較を保証するために、彼らはこれらのデータセットを慎重にスクリーニングし、評価ベンチマークから得られた例を削除しました。トレーニング サンプルの数は元の Orca 論文のわずか 1/10 ですが (これにより、元の論文と比較してモデルのトレーニングにかかるコストと二酸化炭素排出量が大幅に削減されます)、結果として得られた FreeWilly モデルはさまざまなベンチマークで良好なパフォーマンスを示し、合成データセットを使用したアプローチの有効性が検証されました。## **パフォーマンスデータ**これらのモデルの内部評価のために、研究者らは、AGI を組み込んだ EleutherAI の lm-harness ベンチマークを使用しました。その中で、lm-harness ベンチマークは、前述の HuggingFace Open LLM リーダーボードの背後にある EleutherAI 非営利人工知能研究所によって作成されました。AGI は、数学コンテストや司法試験などの「人間中心」の標準テストで基礎となるモデルのパフォーマンスを評価するために Microsoft によって作成されました。どちらの FreeWilly モデルも、複雑な推論、言語の微妙な理解、法律や数学の質問などの特殊な領域を含む複雑な質問への回答など、多くの面で非常に優れたパフォーマンスを発揮します。lm-harness ベンチマークでの 2 つのモデルの評価結果は次のとおりです (これらの FreeWilly テスト結果は、Stability AI 研究者によって評価されました)。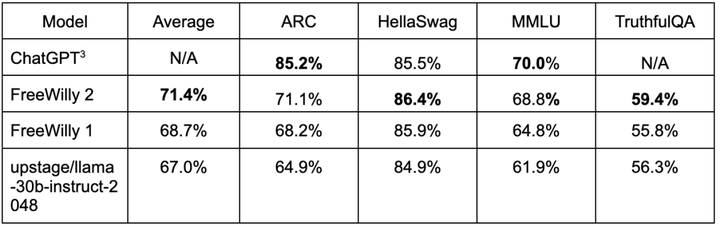 AGI ベンチマークでの 2 つのパフォーマンスは次のとおりです (すべて 0 ショット)。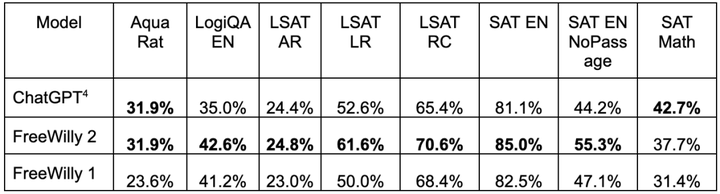 さらに、GPT4ALL ベンチマークで 2 つのモデルをテストしました (すべて 0 ショット)。 全体的に、これら 2 つのモデルのパフォーマンスは非常に優れており、ChatGPT などのトップ AI モデルとの差はさらに縮まっています。モデルを入手したい学生は、下のリンクをクリックしてください。フリーウィリー1:フリーウィリー2:各関係者の反応から判断すると、FreeWilly モデルの登場はあまりにも早すぎたので、皆に少しショックを与えていますが、結局のところ、Llama 2 はまだ発売されてから 3 日しか経っておらず、ランキングの順位も熱くありません。ある研究者は、最近目の手術を受け、1週間ニュースを見なかったが、1年間昏睡状態にあったような気分だったと語った。つまり、これは「まばたきできない」期間です。 ただし、両方のモデルはオープンアクセスですが、Llama 2 とは異なり、研究目的のみに非営利ライセンスの下でリリースされていることに注意することが重要です。 しかし、このようなアプローチはネチズンから疑問を引き起こしました。 これに対し、安定性 AI 研究者らは、この状況は(研究目的のみ)一時的なものであり、将来的には FreeWilly も Llama 2 と同様に商業利用を許可する予定であると回答しました。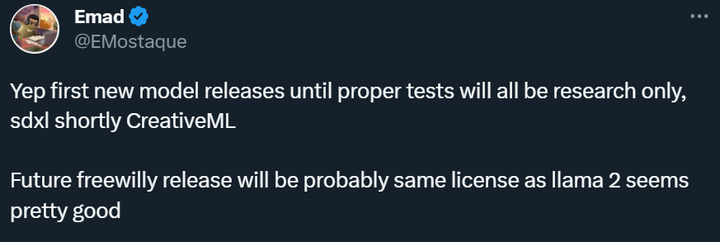 さらに、テストで採用されたベンチマークに疑問を抱く人もいます。 これも現状ではさらに難しい問題です。以前、HuggingFace のリーダーボードで Falcon モデルが Llama を粉砕したというイベントが物議を醸しましたが、その後、このイベントは完全に逆転し、Llama は Falcon に粉砕されていないことが判明し、HuggingFace もこれに合わせてリーダーボードのコードを書き換えました。現在、大規模なモデルが出現しているため、これらのモデルを効果的に評価する方法は依然として議論に値する問題です。したがって、これらの上位モデルについては、より慎重な姿勢を維持し、さらなる評価結果の公表を待つ必要がある。*参考リンク:*


Llama 2 を破り、GPT-3.5 と競合する Stability AI の新モデルは、オープンソースの大型モデル ランキングでトップに立った
出典: ハート・オブ・ザ・マシン
瞬く間に、オープンソースのビッグモデルは再び改良されました。 Google と OpenAI には本当に外堀がないのでしょうか?
「30 分間の昼休みを取ったところですが、私たちの分野はまた変わってしまったのでしょうか?」 最新のオープンソース大型モデルのランキングを見て、AI 分野の起業家は自分の魂に問いかけました。
上の赤いボックス内の「ルーキー」は、Stability AI と CarperAI lab の 2 つの大きなモデル、FreeWilly 1 と FreeWilly 2 です。たった今、彼らは 3 日前に Meta によってリリースされた Llama-2-70b-hf を上回り、HuggingFace の Open LLM リーダーボードのトップに到達することに成功しました。
さらに驚くべきことは、FreeWilly 2 は多くのベンチマークで ChatGPT (GPT-3.5) も上回り、GPT-3.5 と実際に競合できる最初のオープンソース モデルとなったことですが、これは Llama 2 にはできなかったことです。
Stability AI が公開したブログから、これら 2 つの新しいモデルの詳細を確認できます。
データ ソース
FreeWilly モデルのトレーニング方法は、Microsoft が論文「Orca: GPT-4 の複雑な説明トレースからの進歩的学習」で開拓した方法に直接影響を受けています。 FreeWilly のデータ生成プロセスは似ていますが、データのソースに違いがあります。
FreeWilly のデータセットには 600,000 のデータ ポイント (元の Orca 論文で使用されたデータセット サイズの約 10%) が含まれており、Enrico Shippole によって作成された次の高品質の命令データセットから言語モデルをインスピレーションとして生成されました。
このアプローチを使用して、研究者らは、より単純な LLM モデルを使用して 500,000 の例を生成し、より複雑な LLM モデルを使用してさらに 100,000 の例を生成しました。公平な比較を保証するために、彼らはこれらのデータセットを慎重にスクリーニングし、評価ベンチマークから得られた例を削除しました。トレーニング サンプルの数は元の Orca 論文のわずか 1/10 ですが (これにより、元の論文と比較してモデルのトレーニングにかかるコストと二酸化炭素排出量が大幅に削減されます)、結果として得られた FreeWilly モデルはさまざまなベンチマークで良好なパフォーマンスを示し、合成データセットを使用したアプローチの有効性が検証されました。
パフォーマンスデータ
これらのモデルの内部評価のために、研究者らは、AGI を組み込んだ EleutherAI の lm-harness ベンチマークを使用しました。
その中で、lm-harness ベンチマークは、前述の HuggingFace Open LLM リーダーボードの背後にある EleutherAI 非営利人工知能研究所によって作成されました。
AGI は、数学コンテストや司法試験などの「人間中心」の標準テストで基礎となるモデルのパフォーマンスを評価するために Microsoft によって作成されました。
どちらの FreeWilly モデルも、複雑な推論、言語の微妙な理解、法律や数学の質問などの特殊な領域を含む複雑な質問への回答など、多くの面で非常に優れたパフォーマンスを発揮します。
lm-harness ベンチマークでの 2 つのモデルの評価結果は次のとおりです (これらの FreeWilly テスト結果は、Stability AI 研究者によって評価されました)。
フリーウィリー1:
フリーウィリー2:
各関係者の反応から判断すると、FreeWilly モデルの登場はあまりにも早すぎたので、皆に少しショックを与えていますが、結局のところ、Llama 2 はまだ発売されてから 3 日しか経っておらず、ランキングの順位も熱くありません。ある研究者は、最近目の手術を受け、1週間ニュースを見なかったが、1年間昏睡状態にあったような気分だったと語った。つまり、これは「まばたきできない」期間です。
参考リンク: