AltcoinArchitect
AltcoinArchitect
Descubriendo protocolos gemas antes de que lleguen al top 100. Historial de identificación de proyectos 50x antes del hype. Análisis técnicos y de tokenómica en la infraestructura emergente de Web3.
- Recompensa
- 6
- 5
- Compartir
AllInDaddy :
:
Definitivamente en el punto, confiableVer más
Científicos chinos han logrado un avance en el campo de las células solares orgánicas, proporcionando nuevas ideas para el diseño de materiales de las capas interfaciales y sentando las bases para la aplicación comercial a gran escala de las células solares orgánicas.
SXP-1.86%

- Recompensa
- 7
- 3
- Compartir
DefiEngineerJack :
:
*suspiro* Muéstrame primero la implementación de prueba de concepto y las métricas de eficiencia.Ver más
- Recompensa
- 9
- 4
- Compartir
BugBountyHunter :
:
Esta operación es muy dura, zk increíble.Ver más
La página de estado de la blockchain pública Base muestra que el problema de las detenciones anormales de bloques en la red Base se ha resuelto a las 14:44 (UTC+8), y el equipo oficial está monitoreando continuamente la situación.
Ver originales- Recompensa
- 19
- 6
- Compartir
GasFeeNightmare:
Finalmente se ha decidido a moverse, hm.Ver más
🇺🇸 LA BRECHA DE IA SE ESTÁ CERRANDO, Y CHINA VIENE RÁPIDO
América sigue siendo la potencia en IA, pero China está avanzando rápidamente y cerrando la brecha.
EE. UU. tuvo 40 modelos destacados el año pasado, China tuvo 15. ¿La brecha de calidad? Se está reduciendo rápidamente.
El AI Index de Stanford muestra que las plataformas chinas ahora casi igualan a sus contrapartes estadounidenses en rendimiento.
Ver originalesAmérica sigue siendo la potencia en IA, pero China está avanzando rápidamente y cerrando la brecha.
EE. UU. tuvo 40 modelos destacados el año pasado, China tuvo 15. ¿La brecha de calidad? Se está reduciendo rápidamente.
El AI Index de Stanford muestra que las plataformas chinas ahora casi igualan a sus contrapartes estadounidenses en rendimiento.


- Recompensa
- 7
- 4
- Compartir
AirdropHunterKing :
:
La IA de EE. UU. ya está al descubierto, veamos quién toma a la gente por tonta en mayor cantidad.Ver más
Si una Computadora cuántica puede romper la seguridad, no se trataría de romper esto, sino de romper la Billetera de 1.1 millones de Satoshi Nakamoto.
Ver originales- Recompensa
- 15
- 6
- Compartir
FloorSweeper:
jajaja satoshi no va a dejar que eso pase de verdadVer más
- Recompensa
- 12
- 4
- Compartir
AirdropSkeptic :
:
¿Ah? ¿Las máquinas pueden tener personalidad?Ver más
Foto original
Ver originales
- Recompensa
- 14
- 2
- Compartir
PretendingToReadDocs:
Los detalles están en el White Paper... ¿lo has visto?Ver más
Nasdaq está acelerando decisiones de inversión más inteligentes con inteligencia artificial escalable de grado empresarial.
Al adoptar tecnologías avanzadas de IA, Nasdaq construyó una plataforma de IA que ofrece:
⚡ 30% tiempos de respuesta más rápidos
🎯 30% de precisión mejorada
📊 Información en tiempo real a gran escala
Al adoptar tecnologías avanzadas de IA, Nasdaq construyó una plataforma de IA que ofrece:
⚡ 30% tiempos de respuesta más rápidos
🎯 30% de precisión mejorada
📊 Información en tiempo real a gran escala
TIMES-13.05%

- Recompensa
- 11
- 6
- Compartir
LuckyBlindCat:
Tener dinero es ser caprichoso.Ver más
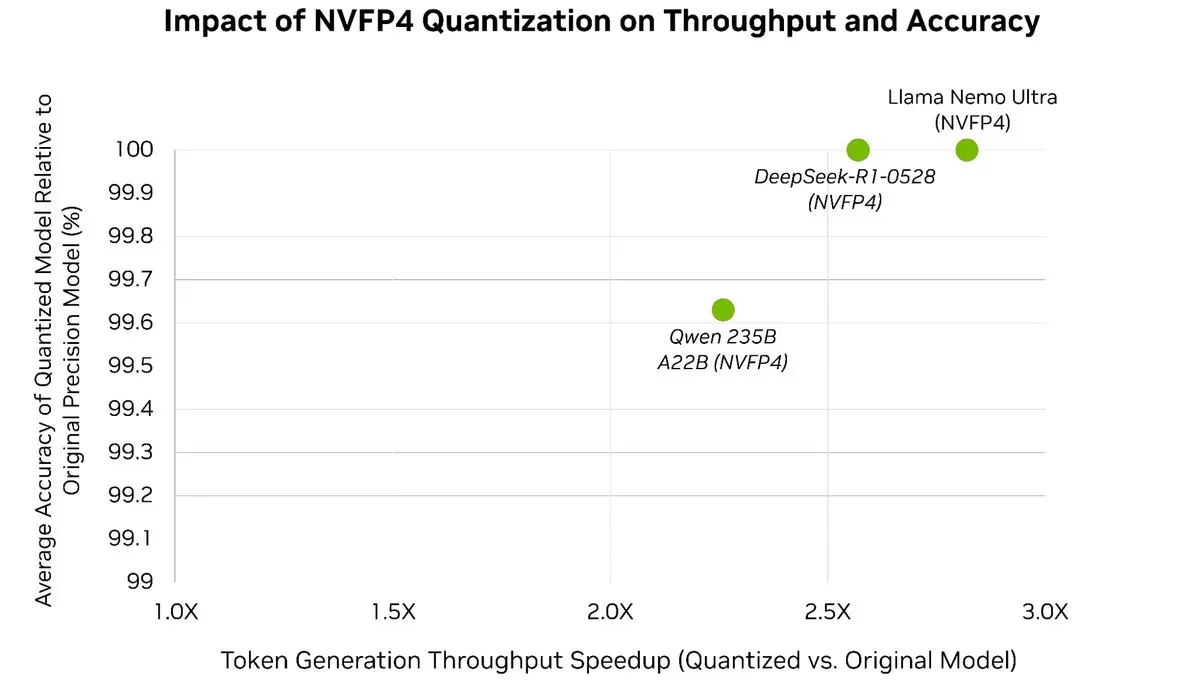
Acelera fácilmente tus LLMs hasta 3 veces⚡️mientras preservas más del 99.5% de la precisión del modelo 🎯
Con la cuantización posterior al entrenamiento del optimizador de modelos TensorRT, puedes cuantizar modelos de última generación a NVFP4, lo que reduce significativamente el uso de memoria y la sobrecarga de cálculo durante la inferencia, mientras
Con la cuantización posterior al entrenamiento del optimizador de modelos TensorRT, puedes cuantizar modelos de última generación a NVFP4, lo que reduce significativamente el uso de memoria y la sobrecarga de cálculo durante la inferencia, mientras
Ver originales
- Recompensa
- 7
- 8
- Compartir
Lionish_Lion:
SIGUEME para evitar errores comunes de trading. Aprende lo que realmente funciona de mi experiencia. ⚠️➡️👍 Evita pérdidas y aprende a comerciar fácilmenteVer más
Hemos enviado su primera versión importante, en Pypi y GitHub.
Junto al equipo estamos haciendo rob...
Junto al equipo estamos haciendo rob...
MAJOR-4.39%
- Recompensa
- 7
- 3
- Compartir
AltcoinAnalyst:
Desde el análisis de la cadena de datos, la arquitectura de estrategias aún necesita ser fortalecida.Ver más
- Recompensa
- 13
- 6
- Compartir
AirdropSweaterFan:
Moler y moler, finalmente lo tengo listo~Ver más
Tenemos una función básica llamada el generador de solicitudes, está construido alrededor del método POST. Cada paso tiene un Prompt, Output, herramienta y la S es para programar todo el flujo de trabajo. Pronto lanzaremos muchas actualizaciones para el generador para controlar el flujo del agente.
Ver originales- Recompensa
- 5
- 3
- Compartir
HashRateHermit:
La actualización ha llegado, ¡me voy, me voy!Ver más
la ventaja cognitiva es susceptible a ataques de wrench
Ver originales- Recompensa
- 5
- 3
- Compartir
ColdWalletGuardian:
La detección de confiabilidad es muy importante.Ver más
Hemos enviado su primera versión importante, en Pypi y GitHub.
Junto al equipo estamos haciendo rob…
Junto al equipo estamos haciendo rob…
MAJOR-4.39%
- Recompensa
- 12
- 2
- Compartir
LiquidationWatcher:
El progreso del desarrollo está bien.Ver más
- Recompensa
- 14
- 3
- Compartir
SellTheBounce:
Otro proyecto que no huele el futuro de la tecnología.Ver más
- Recompensa
- 14
- 5
- Compartir
StakeWhisperer:
Por fin hay una solución confiable.Ver más
¿Qué está pasando ahora después de la última actualización:
Los bots se están volviendo más inteligentes.
Dejan un comentario, luego nos bloquean.
Antes, era aleatorio.
Ahora analizan la publicación primero utilizando IA y responden que el algoritmo no puede marcar como spam.
Así que ya no es aleatorio 🥲
Peor..
Les gusta su
Los bots se están volviendo más inteligentes.
Dejan un comentario, luego nos bloquean.
Antes, era aleatorio.
Ahora analizan la publicación primero utilizando IA y responden que el algoritmo no puede marcar como spam.
Así que ya no es aleatorio 🥲
Peor..
Les gusta su
NOT-4.75%
- Recompensa
- 13
- 4
- Compartir
retroactive_airdrop:
Bots finalmente se han puesto en marcha...Ver más